Continuando con la serie de artículos sobre C/C++, vamos a ver la técnica de programación conocida como Backtracking. Esta técnica se basa en generar todo el espacio de soluciones posibles a un problema dado, pudiendo filtrarse o seleccionar las soluciones que cumplan con ciertas características. Backtracking funciona en forma recursiva, genera árboles de soluciones posibles, recorriendo todo el espectro de posibilidades.
En un primer vistazo Backtracking funciona como un algoritmo de fuerza bruta, que prueba todas las combinaciones posibles, aunque podemos optimizar y mejorar el rendimiento analizando el problema que queremos resolver.Los algoritmos de backtracking suele ser ineficientes, aunque mediante estas optimizaciones se puede moderar la misma, la repetición de cálculos hace que sean ampliamente inferiores a los algoritmos construídos sobre Programación Dinámica. En la próxima entrada analizaremos las diferencias, ahora volvamos a Backtracking :).
Por ejemplo, supongamos que tenemos un conjunto de colores y un mapa dado y queremos colorearlo, de forma que dos países adyacentes no tengan el mismo color. Podemos pensar en este problema como si fuera un grafo, donde los vértices conectados son los países limítrofes.
Este problema puede solucionarse de varias formas, por ejemplo buscando una solución cualquiera, o bien buscar todas las soluciones que existen, o bien la solución óptima que utiliza la menor cantidad de colores.
Lo primero que debemos hacer es formalizar el problema, así logramos identificar los elementos del mismo y se simplifica la tarea de construir el algoritmo. La formalización requiere definir:
Forma de la Solución: Cómo presentaremos la solución al problema. En este caso utilizaremos una tupla de largo fijo N formada por elementos xN, donde N es la cantidad de países que debemos colorear. En la posición 1 colocaremos el color asignado al país 1, en la posición 2 el color del país 2 y así sucesivamente.
Reestricciones Explícitas: El espacio de soluciones, o las soluciones posibles al problema, involucra a un único elemento de la tupla. En este caso indica que cada elemento xi es uno de los países a colorear.
Reestricciones Implícitas: Define las relaciones entre los elementos de la tupla, involucra a varios o todos los elementos de la tupla. En este caso debemos aplicar la reestricción que si dos países son adyacentes no deben tener el mismo color. Por lo que si 1 y 2 son adyacentes en el grafo, entonces los elementos x1 y x2 deben ser distintos.
Función Objetivo: Define lo que queremos maximizar o minimizar en las soluciones generadas. Puede ser la mínima o máxima cantidad de colores por ejemplo.
Predicados de Poda: Nos permite evitar buscar soluciones que es evidente no van a generar una solución útil. Por ejemplo supongamos que buscamos el mínimo de colores, entonces una vez que obtenemos una solución posible al problema sabemos que cualquier solución parcial que se esté construyendo puede ser descartada si la cantidad de colores supera a la ya encontrada.
Con estos elementos definidos podemos pasar a implementar el algoritmo con una idea general de como representar cada elemento. Lo primero que haremos será crear una estructura para nuestra tupla solución:
struct tupla {
int* colores; // Arreglo de colores asignados a los pasies
int* cantVeces; // Cantidad de veces que se usa cada color
int cantColores; // Cantidad total de colores usados
}
El próximo paso es preparar la invocación del algoritmo recursivo, al cual le pasaremos esta tupla para que trabaje:
void invocacion(int n, int k) {
/* La primera tupla será sobre la que se trabajará, en t solo guardamos la mejor solución obtenida */
tupla t, sol;
t.colores = new int[n];
sol.colores = new int[n]; // Colores asignados a los paises, n países
t.cantVeces = new int[k];
sol.cantVeces = new int[k]; // Cantidad de veces de cada color, k colores
for (int i=0; i<n; i++) {
t.colores[i] = 0;
sol.colores[i] = 0; // Inicializamos en cero los colores asignados a países
}
for (int i=0; i<k; i++) {
t.cantVeces[i] = 0;
sol.cantVeces[i] = 0; // Inicializamos en cero la cantidad de veces usada de cada color
}
t.cantColores = 0;
sol.cantColores = 0; // Cantidad de colores usados
colorear(t,sol,0,n); // Invocación al algoritmo
}
Esta función invocación prepara el terreno y luego llama a la función recursiva, pasándole una tupla t donde ir armando las soluciones posibles y sol para guardar la mejor solución encontrada. Esta misma tupla sol se usará para comparar con las tuplas que se van encontrando, de forma de saber si encontramos una mejor solución o no. El tercer parámetro es el primer país sobre el cual comenzar a trabajar, n la cantidad de países total, de forma que el algoritmo puede saber en que momento llega a asignar colores a todos los países y debe detenerse, y k la cantidad de colores para realizar las pruebas con los colores disponibles.
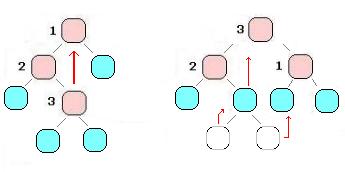
Veamos un ejemplo de la función recursiva colorear:
/* Noten que la tupla sol es pasada por referencia, de modo que cualquier estado de la recurrencia puede modificarla y es visible para todos los demás estados. */
void colorear(tupla t, tupla &sol, int i, int n, int k) {
/* Reestriccion implicita, verificamos que al colocar el color en esta posición
no queden dos paises adyacentes con el mismo color. */
if (Factible(t,i))
if (EsMejor(t,sol))
if (EsSolucion(t,i)) {
Copiar(sol, t)
} else {
for (int color=1; color <= k, color++)
colorear(AsignarColor(t,i,color),sol, i+1, n, k);
}
}
Utilizamos una seria de funciones auxiliares.
Factible: Indica si la tupla t, con colores asignados hasta la posición i no contiene países adyacentes con el mismo color.
EsMejor: Indica si la cantidad de colores utilizados en t es menor que los de sol.
EsSolucion: Indica si se completo la cantidad de países a colorear. Si es así (y como antes vimos que era mejor esta solución que la de sol) procedemos a copiar la misma en sol.
AsignarColor: Como todavía no completamos la cantidad de países debemos asignar un color de los k disponbles al país i, y continuar con la recursión.
Los detalles importantes a tener en cuenta son algunos como que la tupla sol puede ser modificada copiando el contenido de t sobre ella por cualquier paso recursivo que encuentre una mejor solución que la que tenemos hasta el momento. Claro que cuando sol es vacía debemos tener cuidado para no tener una solución vacía como la mejor encontrada. Otro detalle importante es no perder soluciones posibles, por eso en cada paso intentamos asignar todos los colores a cada país, para luego en la nueva llamada verificar la adyacencia.
Una posible implementación de AsignarColor, teniendo en cuenta la estructura de tupla que definimo podría ser:
tupla Asignarcolor(tupla t, int, i, int color) {
t.colores[i] = color;
t.cantVeces[color] = t.cantVeces[color]+1; // Incrementamos la cantidad de veces que usamos el color
if (t.cantVeces[color] == 1)
t.cantColores = t.cantColores +1; // Si el color asignado no habia usado aun, incrementamos cantColores
return t;
}
Este algoritmo construido con Backtracking nos permite generar todas las combinaciones posibles de colores asignados, optimizando de forma que podemos detener la recursión en un paso intermedio al encontrar dos países adyacentes con el mismo color.
En la próxima entrada veremos otro ejemplo de Backtracking similar implementado.
En este mes de febrero se decidirá el destino de la bahia pirata (http://www.thepiratebay.org/), uno de los mayores sitios en Internet para intercambio de archivos e información, y una de las piedras fundamentales de la red torrent.
Pero hay mucho más en juego, no es solo la continuidad de un sitio de jóvenes rebeldes que utilizan el salto tecnológico para intentar cambiar las reglas de juego. De un modelo donde las multinacionales y los medios controlan al flujo de información y las personas reciben lo que estas deciden, a una democrática y a veces caótica red donde todos son iguales y todos pueden crear y distribuir información. Esta libertad es lo que está en juego, la naturaleza descentralizada y sin barreras de Internet.
Para comprender la situación es necesario entender que gracias a la tecnología las reglas de juego deben cambiar, los costos de distribución y acceso a la infromación son prácticamente nulos, lo que ha llevado a la explosión de intercambio de información en la red. Pero los medios tradicionales de información desean mantener el control sobre el flujo y la distribución, imponiendo un modelo de reestricción que no concuerda con las posibilidades que da Internet.
El salto a la fama internacional de The Pirate Bay se produjo en el 2008 cuando por presiones del gobierno norteamericano el gobierno de Suecia intentó cerrar el portal. Durante algunos días el sitio cayó, solo para resurgir algunos días después con servidores distribuídos por todo el mundo y una vitalidad renovada. Frente a este fracaso y la inesperada fama del sitio, el siguiente paso es intentar llevar tras las rejas a las personas detrás del portal.
Las suspicacias ya han comenzado a ser evidentes, desde testigos que son directivos de multinacionales con su probable tendencia a beneficiar a sus empresas, a intentos de bloquear el acceso a los expedientes del caso.
Este juicio será el primero en una larga batalla por mantener la libertad de Internet, contra el modelo de imposición y control propuesto por algunas empresas y grupos de poder. Por primera vez en la historia de la humanidad prácticamente cualquier ser humando tiene la capacidad de hacer eco en el mundo entero, sin necesidad de acceso a influencias y grandes recursos económicos. La posibilidad de no ser un simple condumidor pasivo de información, dando una voz como lo es este msmo blog entre millones de la red.
Por eso, este parece ser el juicio del siglo que definirá como será Internet en el futuro.
Es común al crear estructuras de datos y luego trabajar sobre las mismas, tener la necesidad de realizar búsquedas en forma más frecuente que la necesidad de realizar inserciones. Por ejemplo si tenemos una lista de personas podríamos querer saber si cierta persona está ingresada, o saber información acerca de la misma. Para estos casos en que queremos realizar consultas sobre la estructura de datos puede ser útil trabajar con una estructura de datos que permita realizar búsquedas rápidas (de orden pequeño).
La estructura que vamos a ver es la Tabla de dispersión o Hash, la cual nos permite acceder a una posición dentro de la misma en orden 1, (O(1) caso promedio), realizando una cantidad fija de operaciones. De esta forma nos aseguramos de llegar a donde deberíamos encontrar la información en forma rápida sin importar la cantidad de elementos que tengamos en la estructura.
Un Hash no es más que un arreglo, en el cual podemos usar dos técnicas de ordenamiento interno. Este ordenamiento define donde colocar un elemento al insertar, pudiendo utilizarse dispersion abierta o dispersión cerrada.
Supongamos que tenemos el siguiente Hash:
En principio no es mas que un arreglo, pero crearemos un puntero en cada celda, de forma que podamos tener cualquier tipo de información guardad dentro de las mismas.
typedef struct tablahash{
int totalDisp;
nodoHash* hash[LARGOHASH+1];
};
Dijimos que el hash nos permite acceder en forma rápida a una de las posiciones dentro del mismo, esto se realiza mediante una función de dispersión que dada cierta entrada o valor, nos devuelve el valor dentro del hash donde debemos buscar la información que nos interesa.
Por ejemplo, si tenemos la lista de personas ingresadas por cédula, y le pasamos el numero de cédula 123456789 la función de dispersión nos devolverá la posición X dentro del hash donde debemos buscar la información de esa persona. Una función de dispersión básica pero útil suele ser sumar los valores ASCII de los caracteres y obtener el resto de dividir entre el largo del Hash, ya que no podemos obtener posiciones fuera del Hash mismo.
Un ejemplo de funcìón de dispersión sería el siguiente:
int calcularClaveInsertar(char const* id) {
int i, disp, length;
disp = 0;
length = strlen(id);
Esta función recibe un string y nos devuelve la posición correspondiente al mismo dentro del Hash de largo LARGOHASH.
Ya se habran dado cuenta que podemos tener problemas, que pasa si para dos cédulas diferentes tenemos el mismo resultados de dispersión? Y que sucede si tenemos muchos elementos, más de las posiciones disponibles dentro del hash? Estos casos son llamados «colisiones» ya que la información intenta ocupar el mismo lugar de memoria o posición dentro del hash. Para estos casos es que tenemos que analizar los dos tipos de dispersión posible, abierta y cerrada.
En el caso de la dispersión abierta lo que haremos al tener una colisión será simplemente tener una lista encadenada en cada nodo, por lo que iremos ampliando la lista a medida que tenemos colisiones. Si por ejemplo tenemo el hash de largo 10, e insertamos las cadenas «hola» (104+111+108+97 % 10 = 0), «que» (113+117+101 % 10 = 1), «tal» (116+97+108 % 10 = 1), «hash» (104+97+115+104 % 10 = 0) tendríamos un resultado como el siguiente:
En las posiciones 0 y 1 tuvimos colisiones por lo que tenemos dos listas de dos elementos en cada una. Estos nos lleva a ver que en el peor caso de un hash de dispersión abierta tendremos una única lista de elementos en una sola posición, con lo que nuestro hash será simplemente una lista y no nos será de mucha utilidad.
Por esta razón debemos tomar algunas precauciones al utilizar esta estructura de datos, debemos utilizar una función de dispersión adecuada, es decir que nos devuelva valores lo más distribuidos posibles, debemos utilizar un tamaño de hash mayor a la cantidad de elementos que tendremos o que suponemos llegaremos a tener, y es una buena práctica utilizar un número primo en el largo del hash de forma que nos tengamos muchas colisiones al dividir sobre el largo del hash.
El segundo caso, la dispersión cerrada, no permite la creación de listas, pudiendo haber un solo elemento por cada nodo del hash. Para resolver las colisiones se utilizan funciones de redispersión que permiten buscar otra posición dipsonible para el elemento.
Para las funciones de redispersión tenemos la posibilidad de realizar una función lineal, que al encontrar una colisión sume 1 a la posición encontrada, tratando de encontrar una celda libre a continuación. Por ejemplo si tuviéramos el caso anterior, lo que haríamos hubiera sido insertar la palabra «hola» en la posición 0, luego «que» en la posición 1, cuando vamos a insertar «tal» nos encontramos con la posición 1 ya ocupada, por lo que sumamos 1 y lo insertamos en la posición 2. Cuando vamos a insertar «hash» encontramos la posición 0 ocupada, pasamos a la 1 y lo mismo, sumamos 1 nuevamente y la 2 también esta ocupada por lo que pasamos a la 3 que sí esta libre e insertamos ahí.
Cuando vamos a buscar un elemento al hash caculamos la función de dispersión, por ejemplo para la palabra «tal», obtenemos el valor 1, vamos a esa posición y no lo encontramos. Entonces vamos sumando 1 hasta encontrarlo o que la celda sea vacía.
El problema sucede cuando eliminamos un elemento y «cortamos» esta cadena, de forma que no podemos seguir este procedimiento. Por ejemplo supongamos que eliminamos la palabra «tal», luego queremos saber si «hash» pertenece, para lo cual calculamos la dispersión, obtenemos 0, comenzamos a avanzar sumando 1, pasamos a la posición 1, luego a la 2 y llegamos a una celda vacía. No podemos saber que «hash» está en la próxima posición, ya que la celda vacía indica que se termino la cadena. Podríamos buscar una solución alternativa, por ejemplo marcar las casillas cuando borramos con un valor especial de forma que cuando buscamos y encontramos una de estas casillas sigamos avanzando sin detenernos. Así pasaríamos de la posición 2 a la 3 y econtraríamos «hash».
El problema con la dispersión cerrada lineal es que comenzamos a agrupar los elementos, de forma que terminamos nuevamente con una lista continua dentro del hash y terminamos trabajando como si se tratara de una lista, perdiendo la eficiencia de acceso rápido en el caso promedio.
Tenemos la posibilidad de modificar la función de redispersión, pasando de una lineal a una cuadrática, la cual nos permite dar «saltos» dentro del hash cuando tenemos colisiones. En lugar de sumar 1 al encontrar una colisión sumamos i^2, de esta forma sumamos 0, 1, 4, 9… evitando crear secuencias continuas en un principio. El problema en el caso de la redispersión cuadrática y de que el tamaño del hash es limitado, es que volvemos a caer sobre las mismas posiciones luego de varios saltos, por lo que no utilizamos todo el espacio disponible.
Con la redispersión cuadrática podemos utilizar hasta la mitad del tamaño del hash (si el largo del mismo es de tamaño primo). Es importante realizar un conteo de los elementos y en caso de que el hash este siendo llenado debemos realizar una reestructuración del hash, creando uno nuevo de mayor tamaño primo, por ejemplo un primo cercano al doble, e insertando los elementos del hash anterior en este nuevo hash. Esta operación es bastante costosa, aunque si se tiene cuidado en la elección del tamaño del hash según las características del problema no debería ser una operación frecuente.
Vemos un ejemplo del código de un hash con dispersión abierta. Definimos la estructura de datos como un arreglo con punteros:
// Nodo de un elemento en el hash
typedef struct nodoEtq {
char* idDisposivo;
nodoEtq* sig;
};
typedef struct tablahash {
int totalDisp;
nodoHash* hash[LARGOHASH+1];
};
Necesitaremos inicializar el hash, ya que las posiciones del arreglo son punteros.
// Inicializa todas las posiciones del hash
void inicializarHash (nodoHash** hash) {
int i;
for (i = 0; i <= LARGOHASH; i++)
hash[i] = NULL;
return;
}
tablahash * hash = new tablahash;
inicializarHash(hash->hash);
hash->totalDisp = 0;
Luego necesitaremos la función de dispersión y una función auxiliar para saber si una celda del hash es vacía:
// Calcula la clave a usar para insertar
int calcularClaveInsertar(char const* id) {
int i, disp, length;
disp = 0;
length = strlen(id);
for(i=0; i<length; i++)
disp += id[i];
disp = disp % LARGOHASH;
return disp;
}
// Celda vacia del hash
bool esVaciaCeldaHash(nodoHash** hash, int disp) {
return hash[disp] == NULL;
}
La función para insertar elementos en el Hash:
// Inserta en el hash un identificador
nodoEtq* insertarHash(nodoHash** hash, char* id) {
int disp;
nodoEtq* nodoEtiqueta = new nodoEtq;
nodoHash* nodoH = new nodoHash;
char* idDisp = new char[strlen(id)+1];
// Inovación a la insersión
// Creamos un nuevo nodo, insertamos el char* idD e incrementamos la cantidad de elementos.
nodoEtq* nuevoNodo = new nodoEtq;
nuevoNodo = insertarHash(hash->hash, idD);
gl->totalDisp++;
Como dijimos al comenzar, la idea del hash es buscar elementos dentro del mismo en forma rápida, vemos una función para realizar las búsquedas:
// Indica si pertenece un identificador al hash
nodoEtq* perteneceHash(nodoHash** hash, char const* id) {
nodoEtq* nodo;
int pos;
Al utilizar dispersión abierta tenemos una lista en cada celda, por lo que luego de calcular la dispersión debemos recorrer la lista de ese nodo en busca del elemento o el fin de lista. En caso de encontrar el nodo lo devolvemos, o en caso contrario devolvemos NULL.
Por último, una función para desplegar el hash, puede ser útil para realizar pruebas o ver el estado del hash en un momento dado:
// Función auxiliar para desplegar la lista de cada nodo
void desplegarHashLista(nodoHash* lista) {
nodoHash* recorrer;
Los árboles binarios tienen la utilidad de ordenar la información, separando el conjunto en dos posibilidades, izquierda y derecha, por lo que reducimos el conjunto de búsqueda a la mitad en cada paso. Esto nos lleva a que en un árbol balanceado (si tiene las ramas izquierda y derecha del mismo tamaño +1 o -1) tenemos una altura de Log(n), lo cual hace que las búsquedas sean «rápidas». El problema que tienen los árboles comunes es que pueden degenerar rapidamente en una lista, por ejemplo si insertamos el elemento 1 como raíz, y luego insertamos los números 2, 3, 4, 5… Tendremos inserciones siempre a la derecha, lo que nos lleva a tener una estructura de lista perdiendo la utilidad de dividir a la mitad en cada paso. Para solucionar esto utilizaremos los AVL, o árboles binarios balanceados, que nos permiten después de cada inserción rotar los nodos de forma de que quede ordenado.
Los AVL utilizan el factor de balanceo para decidir si es necesario rotar una rama luego de insertar. Este FB (factor de balanceo) nos dice la diferencia de alturas entre el subárbol izquierdo y el derecho, por lo que restando las alturas de los mismos obtenemos este valor.
En el primer ejemplo del caso anterior tenemos que la primer rama izquierda tiene un desbalanceo, ya que la altura de su subrama izquierda es 2, y la de la derecha es 0, lo que nos da: FB = 2. Tenemos desbalance. En el segundo caso el FB no supera el valor 1, por lo que no hay necesidad de rotar.
Las rotaciones se dividen en dos casos, simples o dobles. Las simples se conocen como LL si son de la rama izquierda, y RR si son de la rama derecha. Las rotaciones dobles son LR o RL, ya que son combinadas y más complejas como sugiere su nombre. Vemos primero las rotaciones simples.
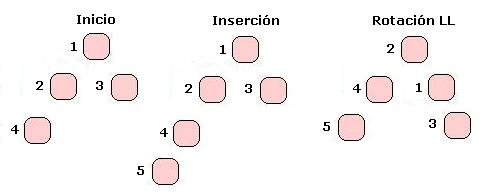
En el caso simple LL, tomemos un nodo 1 que quedará con FB = 2, insertamos un nodo en el subárbol izquierdo de su hijo izquierdo, con lo que tenemos una inserción en la izquierda-izquierda (por eso Left Left). Para balancear el árbol deberemos tomar el hijo izquierdo de 1 (llamémoslo 2), y ponerlo como padre de 1, el hijo derecho de 1 queda en su lugar, el hijo izquierdo de 2 queda en su lugar y el hijo de derecho de 2 debe ir como hijo izquierdo de 1, ya que en su lugar tendremos a 1. Veamos un dibujo:
Lo que hacemos es mover el subárbol que queda con un largo excesivo hacia arriba, sacando al padre para hacer lugar, teniendo cuidado eso si de mantener la relación de mayor menor, lo cual hacemos dejando los subárboles izquierdos de 2 y derecho de 1 en sus lugares (ya que son menores que todos los demas, y mayores respectivamente), y moviendo de lugar el subárbol derecho de 2 hacia el izquierdo de 1. Esto lo podemos hacer ya que este subárbol contiene elementos mayores que los de 2, pero menores que 1.
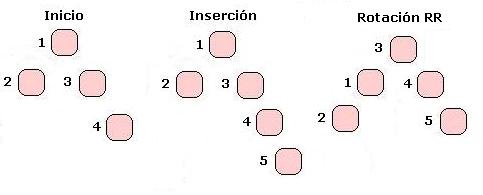
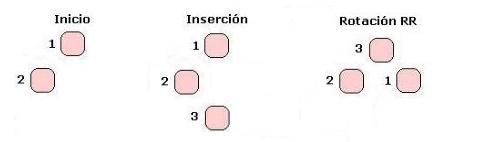
En el caso de la rotación simple RR sucede lo mismo que acabamos de ver, solo que en el caso de insertar a la derecha del hijo derecho:
Hemos visto los dos casos simples, donde insertamos en la rama menor que todos o mayor que todos. Veremos ahora que sucede cuando insertamos en el hijo derecho del subárbol izquierdo, o en el izquierdo del derecho, es decir cruzado.
En este caso lo que haremos será aplicar dos rotaciones simples, con lo cual haremos que el nodo insertado «suba» acortando la altura del árbol. Noten que el nodo que tiene FB = 2 es el nodo 1, y no el nodo 2 que es donde insertamos (en su subárbol derecho). Por lo cual deberemos modificar la altura de sus hijos para reducir el FB a 1.
El proceso que seguiremos será el siguiente, tomamos el nodo en la rama donde se generó el desbalance, en este caso el 2, como la inserción es en el fijo derecho de 2, tomamos este nodo (el 3), y lo guardamos como la nueva raiz. Guardamos los dos hijos del 3 (ya que en realidad el árbol puede ser más amplio, y haber nodos hacia «abajo») y ponemos como su hijo izquierdo a 2, y su hijo derecho a 1. Así sabemos que el orden se mantiene, 3, estaba a la derecha de 2, por lo que es mayor, y a la izquierda de 1, por lo que es menor. Colocado 3 en el lugar de 1, tomamos los dos posibles hijos de 3 que guardamos y los colocamos respectivamente como hijo derecho de 2 al hijo izquierdo, y como hijo izquierdo de 1 al derecho de 3. Otra vez manteniendo el orden.
Veamos un ejemplo gráfico:
En resumen la idea es, cuando detectamos que un nodo tiene FB = 2 (recuerden, en valor absoluto), entonces de acuerdo a sea positivo o negativo tomamos la rama izquierda o la derecha, subimos el nodo correspondiente y reasignamos con cuidado los hijos para no perder el orden. Las operaciones LR y RL, como las LL y RR son simétricas, por lo que el código será idéntico cambiando el hijo seleccionado. Como mencionabamos antes, las operaciones complejas se pueden reducir a dos operaciones simples, por ejemplo la LR podemos reducrila a realziar primero una RR en el hijo izquierdo y luego una LL en la raíz.
Pasemos a los ejemplos de código en C para ver como implementar estas rotaciones.
Lo primero que tenemos que hacer, es hacer una modificación al tipo de dato de árbol binario, ya que queremos tener en cuenta el FB en cada nodo, para detectar un desbalance. Agregaremos un campo int con la altura del nodo actual, lo cual nos permite saber sin tener que sumar recursivamente cada vez la altura de un nodo con sus hijos:
struct AVLNode {
int dato;
AVLNode izq;
AVLNode der;
int altura;
};
El siguiente paso es agregar una función que nos permite conocer la altura de un nodo actual, de forma que nuestro TAD quede bien estructurado, y en caso de ser necesario poder actualizar la misma calculando el FB:
Como ven, pasamos la raíz por referencia, de forma que podemos modificar el puntero y colocar su hijo derecho en su lugar. Pero primero tenemos cuidado de copiar los datos necesarios para no perder las referencias, y de actualizar las alturas correspondientes. Ahora veamos el caso de la rotación doble, para la cual usaremos el hecho de que podemos descomponer la misma en dos rotraciones simples.
Primero realizamos una LL y luego una RR, RotarAVLIzq es la rotación simple en el hijo izquierdo, análoga a RotarAVLDer que acabamos de ver pero sobre el hijo izquierdo de la raíz.
Con esto tenemos las operaciones básicas para balancear, crearemos una funcion que nos permita balancear cuando lo necesitemos, y luego veremos la de inserción que será simple ya que tenemos las tareas divididas en nuestro TAD AVL.
void BalancearAVL (AVLNode* t) {
if(t != NULL) {
if (Altura(t->izq) – Altura(t–>der) == 2) { /* FB indica izquierda */
if (altura (t->izq->izq) >= altura (t->izq->der))
/* simple hacia la izquierda */
RotarAVLIzq(t);
else
/* doble hacia la izquierda */
RotarAVLIzqDoble(t);
}
void InsertarAVL (AVLNode* t, int x) {
if (t == NULL) {
t = ArbolCrearAVL();
ArbolInsertar(t,x);
} else {
if (x < ArbolRaiz(t))
InsertarAVL(&t->izq, x);
else
InsertarAVL(&t->der, x);
BalancearAVL(t);
AlturaCalcular (t);
}
}
Al insertar buscamos la posición del elemento como lo hacemos normalmente en un árbol binario, buscando en derecho o izquierda de acuerdo a la comparación. Una vez que encontramos su posición creamos un nuevo nodo y lo insertamos, al regresar de la recursión debemos balancear los nodos ya que podríamos haber creado un desbalance, actualizando la altura según corresponda.
Con esto completamos nuestro TAD AVL, como ya dijimos tenemos la capacidad de ordenar el árbol y asegurarnos que el orden de búsqueda de un elemento no supere nunca Log(n). Un buen ejercicio de multiestructuras es pensar en la combinación de un AVL con una lista, de forma que podamos buscar determinado valor dentro del AVL, y luego a partir de ese valor podamos recorrer una cantidad de valores ordenados sin tener que buscar cada uno.
Supongamos que tenemos tiempos ordenados en un AVL, y queremos obtener los 10 tiempos siguiente a partir de cierto momento. Entonces lo que podemos hacer es tener un AVL «espejado» en una lista, con lo cual podemos buscar el tiempo deseado en el AVL (o el más cercano a él), y luego de encontrar el mismo saltamos a la lista (mantendremos un puntero a la posición correspondiente en cada nodo del AVL) y recorremos la lista obteniendo los 10 elementos. Así logramos un buen grado de eficiencia, teniendo únicamente que buscar un tiempo en el AVL con un orden Log(n) y luego recorriendo la lista que ya sabemos esta ordenada ya que mantenemos el orden al hacer cada inserción.
En la próxima entrada veremos las tablas de dispersión o Hash, los cuales nos permite hacer búsquedas en un tiempo constante.
La estructura de datos que veremos es la de árboles, esta estructura nos permite organizar información de forma que tenemos una relación de padres e hijos, ordenando por ejemplo por un valor.En el primer caso veremos el árbol binario de búsqueda, donde cada nodo tiene dos ramas y un campo de valor, a la izquierda conectaremos otros nodos de menor valor y a la derecha otros nodos de mayor valor.
Definiremos como NULL un árbol vacío, para cada nodo del árbol tendremos una rama izquierda y una derecha, que son punteros a otros nodos, y un campo para el valor. En este ejemplo usaremos un int para el valor para simplificar, pero podríamos tener un puntero a otra estructura más compleja (y tendríamos que tener forma de poder comparar estos elementos más complejos de forma que podamos ordenar el árbol).
Siguiente la línea de definir un TAD, vamos a crear operaciones básicas sobre esta definición para realizar las tareas esenciales sobre un árbol, como crear, insertar, recorrer y borrar. Por la naturaleza de los árboles tenemos una definición recurrente, y el TAD también trabajará de esta forma, con funciones recursivas sobre la estructura de datos.
Aquí tenemos un TAD para nuestro árbol binario:
arbol * ArbolCrear();
// Crear un árbol vacío.
bool ArbolEsVacio(arbol * t);
// Devuelve true si el árbol ess vacío.
void ArbolInsertar (arbol *& t, int n);
// Inserta el elemento n en el árbol.
int ArbolRaiz(arbol * t);
// Devuelve la raíz del árbol.
arbol * ArbolIzq(arbol * t);
// Devuelve la rama izquierda del árbol.
arbol * ArbolDer(arbol * t);
// Devuelve la rama derecha del árbol.
Y su implementación:
arbol * ArbolCrearVacio() {
return NULL;
}
bool ArbolEsVacio(arbol * t) {
return t == NULL;
}
void ArbolInsertar (arbol *& t, int n) {
if (ArbolEsVacio(t)) {
arbol * nodo = new arbol;
nodo->valor = n;
nodo->izq = ArbolCrearVacio();
nodo->der= ArbolCrearVacio();
t = nodo;
} else {
if (arbol->nodo > n) {
ArbolInsertar (t->izq, n);
} else {
ArbolInsertar (t->der, n);
}
}
}
int ArbolRaiz(arbol * t) {
return t->valor;
}
arbol * ArbolIzq(arbol * t) {
return t->izq;
}
arbol * ArbolDer(arbol * t) {
return t->der;
}
Tengan en cuenta algunos detalles, como por ejemplo al insertar pasamos por referencia el puntero al árbol de forma que podemos modificarlo. Otro detalle es que por ejemplo las operaciones que nos dan las ramas izq y der deben ser utilizadas con precaución, ya que no chequean que el árbol sea vacío. Por lo tanto si llamamos a una de estas operaciones con un árbol vacío tendremos un error grave en el programa. Tenemos que colocar una precondición en el TAD, aclarando que esa operación sólo puede ser utilizada en el caso de que hayamos chequeado que el árbol que le pasamos no es vacio.
arbol * ArbolIzq(arbol * t);
// Devuelve la rama izquierda del árbol.
// Precondición: !ArbolEsVacio(t)
arbol * ArbolDer(arbol * t);
// Devuelve la rama derecha del árbol.
// Precondición: !ArbolEsVacio(t)
Ahora que tenemos el árbol binario podemos organizar información, por ejemplo si tenemos una gran cantidad de numeros y queremos saber si determinado número pertenece al conjunto podemos hacerlo recorriendo el árbol en forma recursiva, chequeando con el nodo actual y recorriendo las ramas. Por ejemplo podríamos hacer algo asi:
Si el nodo en que estamos es vacío, entonces no encontramos el valor buscado, si no es vacío comparamos el valor del nodo actual, si es igual lo encontramos y devolvemos true, si no es igual puede ser mayor o menor por lo que llamamos en forma recursiva a la función con una de las dos ramas para seguir buscando.
Podemos ver que la eficiencia de esta estructura de datos es mucho mayor en las búsquedas, ya que podemos encontrar un elemento sin tener que recorrer todo el conjunto, como nos sucedía en el caso de las listas. Lo que hacemos al buscar en el árbol binario de búsqueda es ir dividiendo el conjunto en dos partes, por lo que cada vez reducimos a la mitad la cantidad de elementos, lo que nos da un orden de búsqueda igual a lograitmo de n, donde n es la cantidad de elementos del conjunto (vermos esto en más detalle más adelante, al finalizar las estructuras y realizar un análisis de órdenes de las mismas).
Por su parte la lista nos obliga a recorrer todo el conjunto de elementos, por lo que podemos tener que recorrer toda la lista para encontrar. Entonces tenemos que para buscar tenemos orden n para la lista, y orden ln(n) para el árbol binario.
Pero no todo es color de rosas en los árboles binarios, ya que tenemos dos complicaciones. La primera es que para insertar un elemento tenemos que recorrer, comparando con los nodos hasta llegar al lugar adecuado del valor dentro del árbol, lo que nos llevar a realizar ln(n) operaciones antes de poder insertar, mientras que con la lista insertamos al comienzo de la misma y no tenemos que recorrer nada, lo que nos da un orden 1 (es decir, una sola operación para insertar sin importar la cantidad de elementos que haya en el conjunto).
El otro problema que tenemos es que no realizamos balanceos del árbol al insertar, a medida que vamos insertando vamos dejando los nodos tal quedan de las comparaciones, pero esto puede provocar que nuestro árbol se transforme en una lista (o en algo parecido a una lista) si se dan ciertas condiciones. Por ejemplo, supongamos que queremos insertar los siguientes números: 10, 8, 6, 4, 2. Entonces siempre estaremos insertando en la rama izquierda, por lo que tendremos en realidad una lista de elementos, no tendremos una distribución pareja de elementos lo cual es necesario para que nuestra búsqueda tenga orden ln(n) (recuerden que este orden se da por ir dividiendo el conjunto en 2 cada vez, reduciendo el tamaño).
Para solucionar este problema veremos en la siguiente entrada, la estructura de datos conocida como AVL, esta estructura sigue la línea del árbol binario que acabamos de ver pero haciendo hincapie en mantener el árbol balanceado en todo momento, es decir que nunca tendremos el problema de que nuestro árbol degenere en una lista y perdamos la posibilidad de buscar en forma rápida dentro del conjunto. Esto lo lograremos rotando las ramas luego de insertar si las mismas quedan desbalanceadas.
Cambiando un poco el objetivo del sitio vamos a investigar un poco sobre las estructuras de datos y algoritmos en C/C++. Para esto vamos a comenzar trabajando con estructuras de datos simples como listas y colas, para luego pasar a estructuras como árboles, árboles binarios de búsqueda, AVLs, Hash y algoritmos complejos.
Para poder seguir los ejemplos les recomiendo utilizar Cygwin si usan Windows para tener todas las herramientas de compilado (g++, archivo make, librerias, etc). Si tienen Linux simplemente instalen los paquetes devel.
Trabajaremos construyendo los tipos abstractos de datos (TADs) que nos permitirán abstraernos de la estructura de punteros y trabajar con operaciones que se encargan de hacer el trabajo sucio =). Esto nos libera de estar revisando detalles de la estructura para poder concentrarnos en como resolver problemas.
Comenzaremos trabajando con las dos estructuras más simples, listas y colas. En las dos estructuras de datos encadenamos elementos en forma simple, la diferencia está en la forma en que una vez que ingresamos los mismos, luego podemos sacarlos. En la lista insertamos en la cabeza y sacamos elementos desde la misma cabeza, este orden es conocido como último en entrar, primero en salir (LIFO siglas en inglés). En el caso de la cola utilizamos el otro orden, primero en entrar primero en salir (FIFO siglas en inglés).
Veamos la definición del tipo de datos para la lista:
typedef struct lista {
int valor;
lista * sig;
};
Con esta definición podemos ir enlazando los nodos de la lista, poniendo en el último el valor NULL en el puntero a sig indicando que termina la lista.
El siguiente paso es definir la lista de operaciones con las cuales vamos a poder trabajar sobre este tipo de datos. Definiremos las siguientes funciones:
lista * ListaCrearVacia();
// Crear una lista de nodos vacia.
bool ListaEsVacia(lista * l);
// Devuelve true si la lista es vacia y false en caso contrario.
void ListaAgregar (lista *& l, int n);
// Agrega el elemento n al comienzo de la lista.
int ListaPrimero(lista * l);
// Devuelve el primer elemento de la lista.
lista * ListaResto(lista * l);
// Devuelve un alias al resto de la lista.
void ListaDestruir(lista * l);
// Libera la memoria asociada a la lista.
Dadas estas operaciones podremos trabajar sobre el tipo de datos con comodidad, creando, insertando, recorriendo y eliminando la estructura sin necesidad de preocuparnos por los punteros que la componen. Por ejemplo si queremos recorrer una lista que tiene elementos podríamos hacer lo siguiente (debemos verificar que no sea vacia primero):
while (!ListaEsVacia(listaDatos)) {
int valor = ListaPrimero(listaDatos);
printf(«\nDato: %d»,valor);
listaDatos= ListaResto(listaDatos);
}
Noten que deberíamos guardar una copia del puntero inicial de la lista para poder volver a recorrerla o bien poder eliminar la memoria de la misma. Si no tenemos este puntero habremos perdido el comienzo de la lista =P.
Entrando un poco en la construcción del TAD, en el caso de la lista tendremos que insertar el elemento al principio de la misma, mientras que en la cola insertamos al final. Esto nos lleva a ver en el caso de la lista si insertamos al comienzo podremos hacerlo rápidamente aunque la lista sea muy grande. Simplemente modificaremos la cabeza de la lista y pondremos el nuevo dato como comienzo. Veamos un ejemplo:
void ListaAgregar (lista *& l, int n) {
lista* nuevoNodo = new lista;
nuevoNodo->valor = n;
nuevoNodo->sig = l;
l = nuevoNodo;
return;
}
Lo que hacemos es crear el nuevo nodo, asignar el valor de entero y luego encadenamos la lista «vieja» como siguiente elemento del nuevo nodo. Esto nos deja la lista l con el nuevo nodo al comienzo.
La definición de las otras funciones es simple, veamos algunas:
lista * ListaCrearVacia() {
lista* l = NULL;
return l;
}
bool ListaEsVacia(lista * l) {
return l == NULL;
}
int ListaPrimero(lista * l) {
return l->valor;
}
lista * ListaResto(lista * l) {
return l->sig;
}
Pero pensemos por un momento en el caso de la cola, para insertar al final tendremos que ir hasta el final de la misma, por lo cual en caso de que tengamos una gran cantidad de datos tendremos que recorrer muchos nodos. Esto no es bueno, como veremos más adelante buscaremos que nuestras estructuras de datos sean eficientes y sean «más lentas» cuantos más datos tengamos en las mismas. Si nuestra estructura se vuelve más lenta a medida que tenemos más datos sufriremos consecuencias a largo plazo, nuestro programa será cada vez más lento.
Para solucionar este problema lo que haremos será tener un puntero al comienzo y otro al final de la cola, lo cual nos permitirá insertar al final de la misma y acceder al comienzo en forma directa, sin tener que recorrer la misma.
typedef struct cola {
lista * inicio;
lista * fin;
};
Noten que utilizaremos la lista, pero con un nodo especial que nos permita acceder al comienzo y al fin de la misma para remover e insertar respectivamente. Las funciones del TAD nos darán las operaciones que podremos utilizar para trabajar sobre este tipo de datos sin preocuparnos de punteros y demás:
cola * ColaCrearVacia();
// Crea una cola vacia.
bool ColaEsVacia(cola * c);
// Devuelve true si la cola es vacia y false en caso contrario.
void ColaEncolar (cola * c, int n);
// Agrega el elemento n a la cola.
int ColaPrimero(cola * c);
// Devuelve el primer elemento de la cola.
void ColaDesencolar(cola * c);
// Elimina el primer elemento de la cola.
void ColaDestruir(cola * c);
// Libera la memoria asociada a la cola.
Para estas operaciones utilizaremos prácticamente el mismo código que para la lista, únicamente teniendo cuidado de utilizar los «accesos directos» según el caso que corresponda, para evitar tener que recorrer toda la cola.
En la próxima entrada veremos árboles binarios de búsqueda, los cuales permiten ordenar la información para encontrar en forma más rapida la misma =)
Ordenar los resultados en los listados suele ser un problema repetido y aburrido de solucionar. Tenemos que cortar la consulta de resultados, luego contar las páginas segun la cantidad de resultados por página, poner links de siguiente, anterior, etc, etc, etc…
En esta entrada les dejo un script para olvidarse de una vez de este tema, un script que se encarga de hacer todo el paginado por su cuenta, simplemente definimos algunos valores y problema solucionado.
Primero que nada el script: «Paginator». El sitio del proyecto lo encuentran en:
http://jpinedo.webcindario.com/scripts/paginator/
Descargan los dos archivos del script y lo primero que tenemos que hacer es configurar el script para que se conecte a la base de datos. Esto lo hacemos en el archivo: paginatorconf.inc.php. Verán que en este archivo definen servidor, usuario, contraseña y DB.
Hecho esto lo único que tenemos que hacer es preparar la consulta SQL tal como la usariamos normalmente, sin LIMIT ni nada. Veamos un ejemplo:
$_pagi_sql = «SELECT * FROM tabla ORDER BY nombre»;
Guardamos en una variable de nombre $_pagi_sql (este nombre es el que usa el script, sirve para no confundirse) la consulta, luego definimos el formato del paginado, es decir la cantidad de resultados por página y el numero de enlaces hacia las páginas de resultados, y llamamos a los dos archivos del paginator, primero al de configuración y luego a paginator.inc.php.
Luego de haber incluído el segundo archivo tendremos en la variable $_pagi_result el resultado de la consulta. Además tenemos otras variables que guardan todos los datos que necesitamos, como cantidad de resutlados, número de enlaces y demás, veamos como podemos desplegar la información:
<tfoot>
<tr><th colspan=2 width=100%>
Resultados: Desde <?=$_pagi_desde?> hasta <?=$_pagi_hasta?> (Total: <?=$_pagi_totalReg?>)
<br />Página: <?=$_pagi_navegacion?>
</th></tr>
</tfoot>
</table>
Recorremos los resultados obtenidos, y con la variable $_pagi_navegacion desplegamos la navegación con los links de siguiente, anterior y links directo a las páginas. así de simple :).
Para los casos en que utilizan variables GET para su sitio, no hay problema, ya que las variables GET que utiliza el navegador no borran las de ustedes, el script se encarga de propagar o «poner en su sitio» las variables GET que tenga la URL para no romper la misma ;).
Enviar mails con PHP suele ser sencillo, utilizando la funcion mail() podemos hacerlo aunque no tenemos prácticamente fleixbilidad ni opciones. Casos típicos son cuando queremos enviar mails por smtp, utilizando una cuenta en particular, o nuestro servidor no tiene configurado un servidor local para PHP, o necesitamos una conexion SSL, etc.
Para estos casos podemos usar la clase phpmailer, que nos da todas estas opciones y más. La clase la pueden descargar de: phpmailer.codeworxtech.com
Lo único que necesitamos hacer luego de tener la clase descargada y colocada nuestro sitio, es incluir el archivo de la misma e instancia la clase:
require(«phpmailer/class.phpmailer.php»);
$mail = new PHPMailer();
Hecho esto pasamos a definir mail de origen, destino, nombre, etc.:
$mail->From = $mailfrom; // Mail de origen
$mail->FromName = $name; // Nombre del que envia
$mail->AddAddress($para); // Mail destino, podemos agregar muchas direcciones
$mail->AddReplyTo($mailfrom); // Mail de respuesta
Luego definimos el contenido del mail:
$mail->WordWrap = 50; // Largo de las lineas
$mail->IsHTML(true); // Podemos incluir tags html
$mail->Subject = «Consulta formulario Web: $name»;
$mail->Body = «Nombre: $name \n<br />».
«Email: $mailfrom \n<br />».
«Tel: $tel \n<br />».
«Mensaje: $info \n<br />»;
$mail->AltBody = strip_tags($mail->Body); // Este es el contenido alternativo sin html
Podemos adjuntar archivos simplemente agregando los mismos de la siguiente forma:
$mail->AddAttachment(«nombredearchivo.txt»); // Ingresamos la ruta del archivo
Y ahora viene la parte divertida (no solo me pica el…errr), definimos el servidor que enviara el mail, podemos definir tipo de servidor, autenticacion, usuario, contraseña, etc. Vemos ejemplo de las posibilidades que tenemos.
Si vamos a enviar mail desde el servidor local sin configuración especial podemos usar:
$mail->Host = ‘localhost’;
Si necesitamos utilizar una casilla de correo smtp, con user y pass:
$mail->IsSMTP(); // vamos a conectarnos a un servidor SMTP
$mail->Host = «mail.servidor.com»; // direccion del servidor
$mail->SMTPAuth = true; // usaremos autenticacion
$mail->Username = «info@servidor.com»; // usuario
$mail->Password = «pass»; // contraseña
Si necesitamos una conexion con SSL, por ejemplo para enviar un mail desde PHP con gmail:
Como ven esta clase es muy flexible y nos olvidamos de tener que manejar nosotros mismos conexiones complejas o con cabeceras especiales. Podemos simplificarnos mucho la vida utilizando phpmailer para enviar mails.
Ya para enviar el correo, simplemente utilizamos la siguiente linea:
$mail->Send();
Podemos poner esa llinea dentro de un if para saber si quedo todo bien configurado y se pudo enviar el email, de la siguiente forma:
if ($mail->Send())
echo «Enviado»;
else
echo «Error en el envio de mail»;
En cualquier sitio que requiera programación, ya sean noticias, productos, categorías, etc., necesitamos agregar URLs que tienen parámetros. Estos parámetros son los que indican a nuestro código la información a cargar, pero los buscadores no ven con buenos ojos estas consultas con parámetros. Por ejemplo:
http://www.sitio.com/noticias.php?date=20080201
Esta url además de no ser amigable para los buacadores no lo es para los usuarios. Si alguien busca en el historial y ve esa dirección no va a recordar fácilmente de que se trata.
Para poder llevar esta URL a algo mas prolijo utilizaremos mod_rewrite de Apache y un archivo .htaccess. Buscamos lograr una url como la siguiente:
http://www.sitio.com/noticias/2008/02/01
Primero que nada necesitamos saber si nuestro servidor Apache tiene habilitado mod_rewrite, para esto podemos ver en el archivo de configuración httpd.conf el cual debe tener descomentada la línea siguiente:
LoadModule rewrite_module modules/mod_rewrite.so
Nota para los que tengan Windows, pueden tener problemas al probar este módulo, en Linux anda a las mil maravillas.
En caso de que el servidor no soporte el módulo o que escriban mal el archivo .htaccess van a ver un mensaje de error por lo que es recomendable probar primero todo en un directorio separado del sitio principal para no bloquear todo haciendo pruebas. Si tuvieron que modificar el archivo httpd.conf van a necesitar reiniciar el servidor.
El siguiente paso es el de crear el archivo .htaccess, nuevamente los que tengan Windows pueden tener algun problema al intentar crear un archivo que empieza con un punto, lo que pueden hacer es abrir el bloc de notas y en Archivo > Guardar Como eligen «Todos los Archivos» y ponen el nombre .htaccess para guardar.
Empecemos con un archivo básico de ejemplo:
RewriteEngine On
RewriteBase /
RewriteRule ^login/ /login.php [L]
Lo que haremos será poner una URL en el navegador, pero queremos que nuestro script reciba el código como si nada hubiera sucedido, para esto reescribiremos las URLs. Las dos primeras líneas indican que vamos a activar el módulo de reescritura y luego indicamos la ruta para esta operación.
A continuación lo que hacemos es indicar nuestra primera regla de modificación, queremos que cuando alguien ingresa a www.nuestrositio.com/login/, en realidad lo envíe al archivo login.php. Para esto indicamos la palabra a buscar y luego indicamos el archivo php al cual se reenviará el pedido. Claro que esto sucede del lado del servidor, por lo que el visitante del sitio no ve nada «raro» al acceder.
Veamos ahora un ejemplo en el que queremos pasar parámetros en forma limpia a un archivo php:
Podemos agregar una segunda regla, una por línea y manteniendo las dos primeras línea del archivo .htaccess. Esta nueva regla utiliza una cadena de texto «noticias» y luego una expresión regular para pasar al archivo php un parámetro como variable GET[‘id’].
La expresión regular de este ejemplo recibe números del 0 al 9 (el asterisco indica que pueden ser muchos) y los pasa al archivo noticias.php donde aparece la variable $1. Si tenemos varios parámetros podemos poner varias expresiones regulares y variables para cada una $1, $2, $3…
Vemos ahora un ejemplo en el cual pasamos letras también:
En este caso la expresión regular acepta letras de la «a» a la «z», de la «A» a la «Z» (las expresiones son sensibles a mayúsculas, por eso ponemos los dos casos), también acepta números así como algunos caracteres: ( ) + % _ –
Noten que para los paréntesis necesitamos utilizar la barra de escape «\»la cual indica que vamos a poner un caracter que la expresión puede «confundir» con otra cosa. Este caracter nos sirve para estos casos especiales.
Para seguir ahondando en ejemplos necesitamos tener un manejo de expresiones regulares, tema que escapa a esta entrada específica.
Estamos dispuestos a publicar todos los secretos, aun aquellos que creemos nos dan seguridad? Todos los secretos, desde nuestros impuestos a manuales de tortura pasando por informacion tecnica de armamento y guiones de cine.
Este es el objetivo de Wikileaks, un sitio dedicado a publicar los secretos del mundo, con un objetivo, salvar al periodismo de su patético estado vegetal. En el sitio podremos encontrar desde documentos de como se vacio al estado de Kenya, a material clasificado del Pentágono para ocultar a prisioneros de Guantánamo torturados, así como pruebas de lavado de dinero por bancos de suiza.
Claro que todas estas publicaciones provocaron reacciones, juicios, demandas, amenazas e informes sobre la irresponsabilidad de este emprendimiento, lo cual unicamente provocó el crecimiento explosivo y el lanzamiento a la fama mundial del sitio. Bloqueado durante algunos días en Estados Unidos, duramente criticado por el Pentágono y demandado por corporaciones de todo el mundo, los administradores del sitio no se dejarían vencer tan fácilmente, con servidores distribuídos en todo el mundo y una masa de público que transformó en portavoz del mensaje el sitio se ha visto beneficiado por la atención de los medios y periodismo en general.
Los críticos del sitio plantean que los secretos son necesarios en el mundo actual y que el ideal planteado por Wikileaks es tonto e inocente. Claro que en un mundo donde la capacidad de comunicación se multiplica día a día, no se ven los efectos sobre la libertad de información y la investigación periodística crítica. Es esto lo que Wikileaks plantea salvar, de una forma directa y agresiva, pero clara, publicar todos los secretos sin piedad.